

Voice is the most helpful interface when your hands and eyes are busy, and the least forgiving when it lags or mishears. This article focuses on the real‑world blockers that make assistants feel robotic, how to measure them, and the engineering patterns that make voice interactions feel like a conversation.
Why “natural” is hard
Humans process and respond in ~200–300 ms. Anything slower feels laggy or robotic. Meanwhile, real‑world audio is messy: echo-prone kitchens, car cabins at 70 mph, roommates talking over you, code‑switching (“Set an alarm at saat baje”). To feel natural, a voice system must:
- Hear correctly: Far‑field capture, beamforming, echo cancellation, and noise suppression feeding streaming automatic speech recognition (ASR) with strong diarization and voice activity detection (VAD).
- Understand on the fly: Incremental natural language understanding (NLU) that updates intent as transcripts stream; support disfluencies, partial words, and barge‑in corrections.
- Respond without awkward pauses: Streaming text-to-speech (TTS) with low prosody jitter and smart endpointing so replies start as the user finishes.
- Recover gracefully: Repair strategies (“Did you mean…?”), confirmations for destructive actions, and short‑term memory for context.
- Feel immediate: Begin speaking ~150–250 ms after the user stops, at p95, and keep p99 under control with pre‑warm and shedding.
- Be interruptible: Let users cut in anytime; pause TTS, checkpoint state, resume or revise mid‑utterance.
- Repair mishears: Offer top‑K clarifications and slot‑level fixes so users don’t repeat the whole request.
- Degrade gracefully: Keep working (alarms, timers, local media, cached facts) when connectivity blips; reconcile on resume.
- Stay consistent across contexts: Handle rooms, cars, TV bleed, and multiple speakers with diarization and echo references.
Core challenges (and how to tackle them)
Designing Voice‑Only Interaction and Turn‑Taking
Why it matters: Most real use happens when your hands and eyes are busy, cooking, driving, working out. If the assistant doesn’t know when to speak or listen, it feels awkward fast.
What good looks like: The assistant starts talking right as you finish, uses tiny earcons/short lead‑ins instead of long preambles, and remembers quick references like “that one.”
How to build it: Think of the conversation as a simple state machine that supports overlapping turns. Tune endpointing and prosody so the assistant starts speaking as the user yields the floor, and keep a small working memory for references and quick repairs (for example, “actually, 7 not 11”).
Metrics to watch: Turn Start Latency, Turn Overlap Rate. A/B prosody and earcons.
Achieving Ultra‑Low Latency for Real‑Time Interaction
Why it matters: Humans expect a reply within ~300 ms. Anything slower feels like talking to a call center Interactive Voice Response (IVR).
What good looks like: You stop, it speaks, consistently. p95 end‑of‑speech to first‑audio ≤ 300 ms; p99 doesn’t spike.
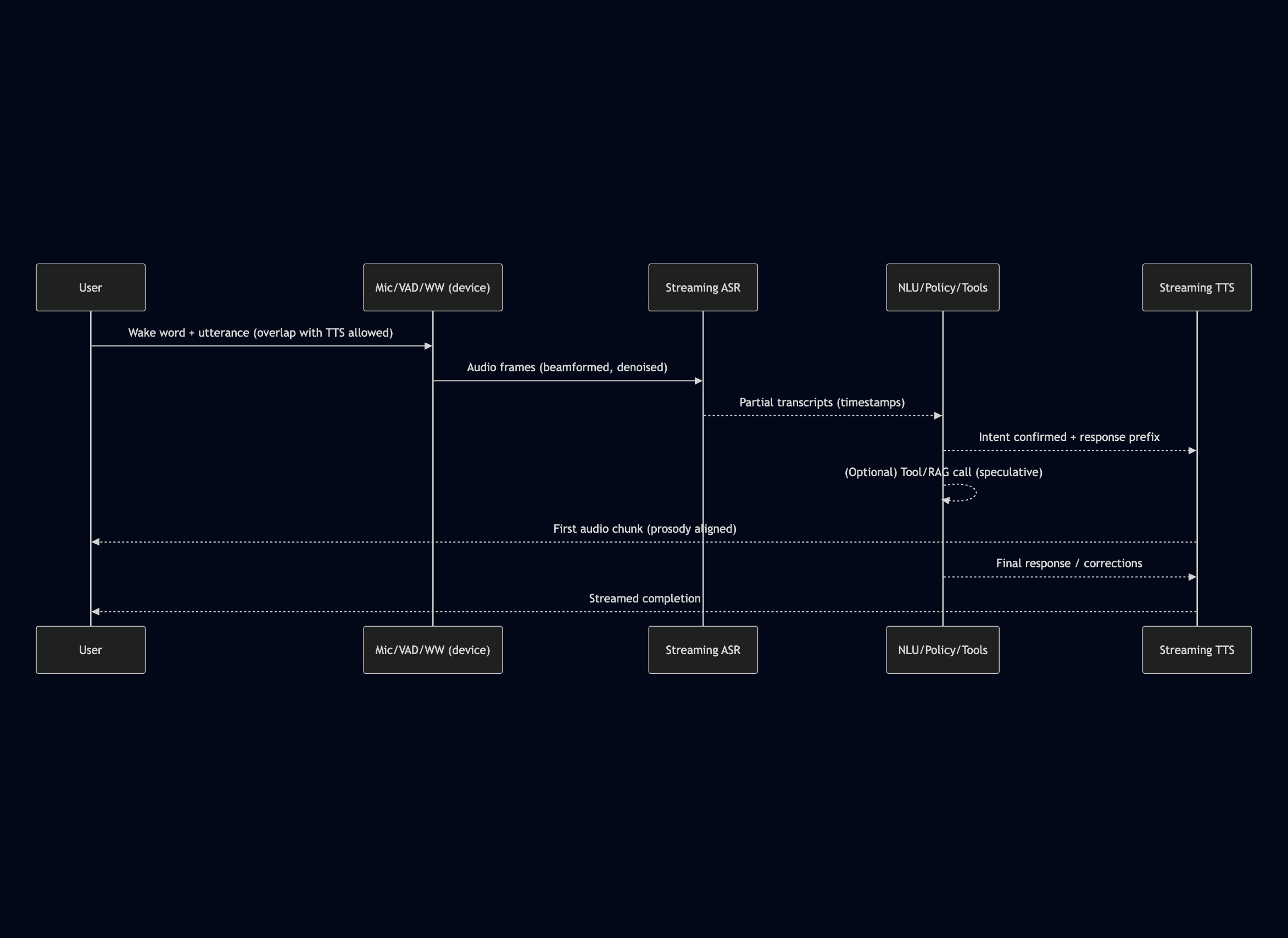
How to build it: Set a latency budget for each hop (device → edge → cloud). Stream the pipeline end to end: automatic speech recognition (ASR) partials feed incremental natural language understanding (NLU), which starts streaming text‑to‑speech (TTS). Detect the end of speech early and allow late revisions. Keep the first hop on the device, speculate likely tool or large language model (LLM) results, cache aggressively, and reserve graphics processing unit (GPU) capacity for short jobs.
Metrics to watch: end‑of‑speech to first‑audio p95/p99. Pre‑warm hot paths; shed non‑critical work under load.
Keeping Responses Short and Relevant
Why it matters: Rambling answers tank trust, and make users reach for their phone.
What good looks like: One‑breath answers by default; details only when asked (“tell me more”).
How to build it: Set clear limits on text‑to‑speech (TTS) length and speaking rate, and summarize tool outputs before speaking. Use a dialog policy that delivers the answer first and only adds context when requested, with an explicit “tell me more” path for deeper detail.
Metrics to watch: Average spoken duration, Listen‑Back Rate (how often users say “what?”).
Handling Interruptions and Barge‑In
Why it matters: People change their minds mid‑sentence. If the assistant cannot stop and pivot gracefully, the conversation breaks.
What good looks like: You interrupt and it immediately pauses, preserves context, and continues correctly. It never confuses its own voice for yours.
How to build it: Make text‑to‑speech (TTS) fully interruptible. Maintain an echo reference so automatic speech recognition (ASR) ignores the assistant’s audio. Provide slot‑level repair turns, and ask for confirmation only when the action is risky or confidence is low. Offer clear top‑K clarifications (for example, Alex versus Alexa).
Metrics to watch: Barge‑in reaction time and Successful repair rate, tested on noisy, real‑room audio.
Filtering Background and Non‑Directed Speech
Why it matters: Living rooms have televisions, kitchens have clatter, and offices have coworkers. False accepts are frustrating and feel invasive.
What good looks like: It wakes for you—not for the television—and it ignores side chatter and off‑policy requests.
How to build it: Combine voice activity detection (VAD), speaker diarization, and the wake word, tuned per room profile. Use an echo reference from device playback. Add intent gating to reject low‑entropy, non‑directed speech. Keep privacy‑first defaults: on‑device hotword detection, ephemeral transcripts, and clear indicators when audio leaves the device.
Metrics to watch: False accepts per hour and Non‑directed speech rejection, sliced by room and device.
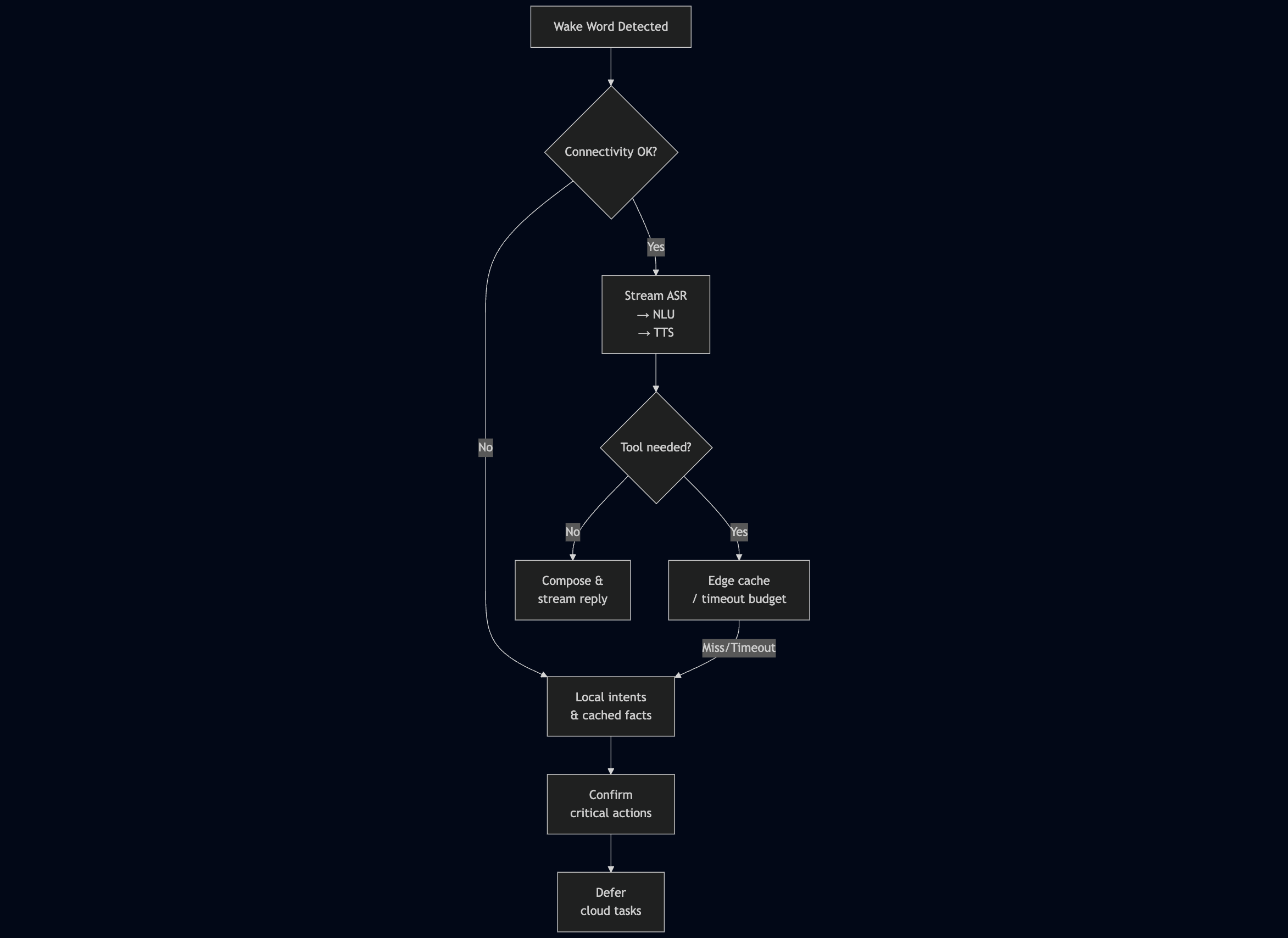
Ensuring Reliability with Intermittent Connectivity
Why it matters: Networks fail—elevators, tunnels, and congested Wi‑Fi happen. The assistant still needs to help.
What good looks like: Timers fire, music pauses, and quick facts work offline. When the connection returns, longer tasks resume without losing state.
How to build it: Provide offline fallbacks (alarms, timers, local media, cached retrieval‑augmented generation facts). Use jitter buffers, forward error correction (FEC), retry budgets, and circuit breakers for tools. Persist short‑term dialog state so interactions resume cleanly.
Metrics to watch: Degraded‑mode success rate and Reconnect time.
Managing Power Consumption and Battery Life
Why it matters: On wearables, the best feature is a battery that lasts. Without power, there is no assistant.
What good looks like: All‑day standby, a responsive first hop, and no surprise drains.
How to build it: Keep the first hop on the device with duty‑cycled microphones. Use frame‑skipping encoders and context‑aware neural codecs. Batch background synchronization, cache embeddings locally, and keep large models off critical cores.
Metrics to watch: Milliwatts (mW) per active minute, Watt‑hours (Wh) per successful task, and Standby drain per day.
Key SLOs
- Automatic Speech Recognition (ASR) and Natural Language Understanding (NLU): Track Word Error Rate (WER) by domain, accent, noise condition, and device, along with intent and slot F1. (Why) Mishears drive task failure; (How) use human‑labeled golden sets and shadow traffic; alert on regressions greater than X percent in any stratum.
- Latency & turns: end‑of‑speech to first‑audio (p50/p95/p99), Turn Overlap (starts within 150–250 ms), Barge‑in reaction time. (Why) perceived snappiness; (Targets) p95 ≤ 300 ms; page when p99 or overlap drifts.
- Outcomes: Task Success, Repair Rate (saves after correction), Degraded‑Mode Success (offline/limited). (Why) business impact; (How) break out by domain/device and set minimum bars per domain.
- Brevity and helpfulness: Average spoken duration, Listen‑Back Rate (“what?”), dissatisfaction (DSAT) taxonomy. (Why) cognitive load; (Targets) median under one breath; review top DSAT categories weekly.
- Power: milliwatts per active minute, watt‑hours per task, and standby drain per day. (Why) wearables user experience (UX); (How) budget per device class and trigger power sweeps on regressions.
Dashboards: Slice by device/locale/context; annotate deploy IDs; pair time‑series with a fixed golden audio set for regression checks.
Architectural blueprint (reference)
Fallback & resilience flow
Final thought
The breakthrough isn’t a bigger model; it’s a tighter system. Natural voice assistants emerge when capture, ASR, NLU, policy, tools, and TTS are engineered to stream together, fail gracefully, and respect ruthless latency budgets. Nail that, and the assistant stops feeling like an app and starts feeling like a conversation.
 Price Prediction 2025, 2026-2030")



